As we celebrate the yearly Open Access Week, we are proud to announce that RePEc now indexes over one million working papers, as pre-prints are typically called in Economics. Working papers have long been at the heart of economic research, and RePEc has been there from its start to help with their dissemination.
The theme of the Open Access Week this year is “Open with Purpose: Taking Action to Build Structural Equity and Inclusion.” This theme resonates strongly with RePEc. Indeed, our mission is to enhance for everyone the dissemination of economic research. RePEc was created specifically to help those who were outside the informal dissemination networks for working papers and allow them to follow the research frontier. Indeed, as publication delays from submission to print take years, the working paper is the best informer of current research. Before RePEc, one needed to be “within the club” to be even aware of new papers, let alone have access to them. With RePEc, anybody can find them and in most cases also read them, years before they get published in a journal.
The current Covid-19 pandemic has highlighted the need to rapid access to ungated research for everyone. While this has been a problem in other fields, this has not been the case in Economics. At the time of this writing, over 6000 works are available through RePEc, and almost all can be downloaded for free.
Equity and inclusion are thus about giving the same chance at reading and getting read. All services are free and open to every one. Authors get their institution to participate and index their research output, for free (instructions). If the institution is unwilling to do so, authors can upload their papers, for example at MPRA, again for free. Readers can leverage the various RePEc services to discover new research (and older, too), for free. The metadata is even relayed to other popular indexing services, you guessed it, for free (even if some of them do require a subscription). But beyond being free, it is important to note that no one will be rejected, as long as their writing is about economics and is academic research. And everybody can access the papers.
We are happy to see that authors from the Southern Hemisphere are increasingly submitting the papers to RePEc. As RePEc was built specifically for those who not have the privilege to work or study in the top universities, we are particularly proud at seeing the increasing share of readers from Southern countries, too. In total the traffic we see splits in the following way: Asia 35%, Europe 24%, North America 19%, Africa 10%, South and Central America 9%, Oceania 3%. We saw users from every country over the last year.
While the penetration of open access journals is likely lower in economics compared to other fields, we have with our working paper culture a powerful substitute. Even after a paper has been published in a journal, we observe that the working paper version is read many times more that the article. While a journal publication may still bring some prestige, getting read (and ultimately cited) requires a working paper. The publication process in a journal is littered with hurdles that may be to high for some,and thus some good research may not get visible that way. But working papers give everyone a fair chance.



 Posted by Christian Zimmermann
Posted by Christian Zimmermann 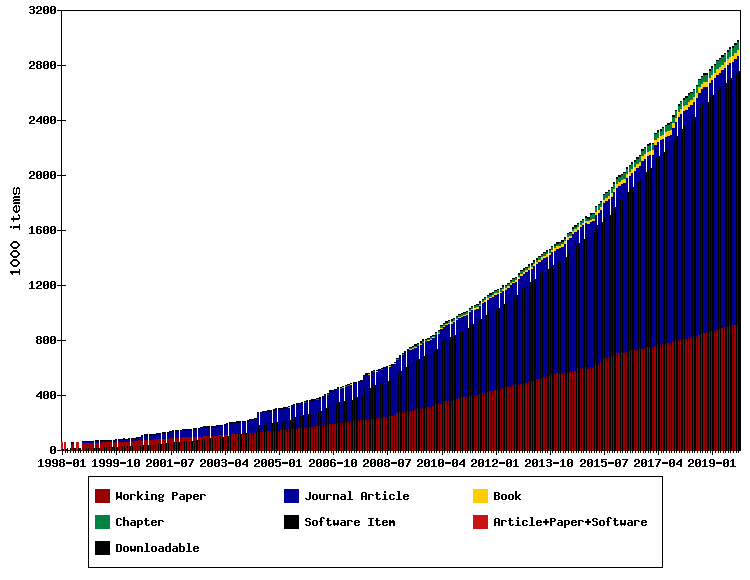







You must be logged in to post a comment.